- Published on
Caso práctico curso Especialista en Inteligencia Artificial - Conclusiones
- Authors

- Name
- Jesus Herman Marina
- @jhmarina2
- Caso práctico del curso de especialista en IA
- Presentación del caso practico
- Objetivos del proyecto.
- Datos utilizados.
- Modelos que habremos utilizado.
- Entrenamiento del modelo.
- Evaluación y métricas de rendimiento.
- Aspectos éticos y de IA responsable.
- Implementación y despliegue.
- Impacto y beneficios.
- Desafíos y limitaciones.
- Futuras mejoras en próximos pasos.
Caso práctico del curso de especialista en IA
Después de semanas de trabajo, finalmente llego a la conclusión de mi proyecto práctico de reconocimiento facial como parte del curso de especialista en inteligencia artificial. Durante este proceso, documenté los desafíos técnicos, las soluciones que implementé y la evolución del proyecto a través de dos artículos anteriores. Sin embargo, en esta última etapa decidí centrarme completamente en terminar el proyecto, lo que me llevó a dejar de escribir artículos de manera diaria.
A continuación os paso la presentación que realicé del caso práctico.
Presentación del caso practico
Objetivos del proyecto.
El objetivo principal de este proyecto es desarrollar una aplicación de reconocimiento facial en tiempo real capaz de detectar, identificar y registrar los rostros que aparecen frente a una cámara. Esta aplicación debe permitir una implementación eficiente en un entorno web mediante la utilización de tecnologías modernas como Flask y Docker, para asegurar que pueda ser fácilmente desplegada en cualquier infraestructura, incluidos contenedores de Kubernetes.
Datos utilizados.
Los datos utilizados para entrenar el modelo consisten en imágenes de rostros que se almacenan en un directorio específico (imagenes/). Estas imágenes se procesan utilizando la biblioteca face_recognition para obtener las codificaciones faciales. Cada imagen debe contener un solo rostro, y es importante que las imágenes estén en formato .jpg o .png. Los datos también incluyen las codificaciones faciales y los nombres asociados, que se guardan en un archivo de tipo pickle (codificaciones.pkl).
Modelos que habremos utilizado.
El modelo de reconocimiento facial utilizado se basa en la biblioteca face_recognition, que implementa un algoritmo de reconocimiento facial basado en redes neuronales convolucionales (CNN). La biblioteca utiliza el modelo de dlib para la detección de rostros y extracción de codificaciones faciales, que luego se comparan con los datos de rostros previamente conocidos para identificar a las personas.
Se utilizan los siguientes modelos de la libreria:
- Modelo de detección de caras: Usando una CNN.
- Modelo de codificación facial: Transforma la cara en un vector de características que puede ser comparado con otras caras.
Entrenamiento del modelo.
El entrenamiento del modelo en este proyecto es bastante simple, ya que el modelo en sí está pre-entrenado. Lo que se entrena aquí son las codificaciones faciales de los rostros conocidos. Para cada imagen de rostro, se extraen las características faciales utilizando el modelo de face_recognition. Estas codificaciones faciales se asocian con los nombres de las personas y se almacenan en un archivo para su uso posterior durante la identificación en tiempo real.
El proceso de entrenamiento incluye:
- Cargar imágenes de rostros.
- Preprocesamiento de las imagenes
- Conversión a RGB: Este paso es crucial porque algunas imágenes pueden estar en otros formatos de color como CMYK o escala de grises, que no son adecuados para el modelo de reconocimiento facial, que requiere imágenes en formato RGB.
- Conversión a numpy array: Este formato es más fácil de manejar para las operaciones de detección y reconocimiento de caras que realiza la biblioteca face_recognition.
- Validación de la imagen: Se verifica que las imágenes sean del tipo uint8 y que tengan tres canales de color (correspondientes a los colores RGB). Si una imagen no cumple con estas condiciones, se omite su procesamiento.
- Extraer las codificaciones faciales.
- Guardar las codificaciones y los nombres en un archivo para que puedan ser utilizados en la identificación.
- Se comprueba tambien que no haya codificaciones duplicadas.
Evaluación y métricas de rendimiento.
La evaluación del modelo se realiza observando la precisión con la que el sistema reconoce los rostros en tiempo real. Algunas métricas importantes que se pueden considerar para evaluar el rendimiento son:
- Precisión: La capacidad del sistema para identificar correctamente los rostros conocidos.
- Tasa de falsos positivos/negativos: Es importante monitorear si el sistema identifica erróneamente a personas que no están en la base de datos (falsos positivos) o si falla en reconocer a una persona que debería ser identificada (falsos negativos). En mi caso concreto, esto no ha sido el caso, puesto que solamente he probado el modelo con 4 imagenes y no ha fallado.
En este caso, no se requiere una validación cruzada tradicional, ya que el modelo preentrenado se utiliza principalmente para la extracción de características.
Aspectos éticos y de IA responsable.
- Privacidad: La recolección y el uso de datos biométricos, como rostros, deben realizarse con el consentimiento explícito de las personas involucradas.
- Sesgos: Es importante que el sistema sea justo y preciso para todas las personas, independientemente de su raza, género u otros factores.
- Transparencia: Debe quedar claro cómo se utilizan los datos recolectados y cuáles son las limitaciones del sistema.
- Seguridad de los datos: Las imágenes y codificaciones faciales deben ser almacenadas de manera segura, protegiendo la información personal de los usuarios.
Implementación y despliegue.
La aplicación ha sido implementada utilizando Python y la biblioteca Flask para crear un servidor web que procesa las imágenes en tiempo real. Se ha integrado un modelo de reconocimiento facial que se entrena localmente y se despliega como parte del servidor.
El despliegue se facilita mediante Docker, que permite empaquetar la aplicación en un contenedor. Esto asegura que la aplicación pueda ejecutarse de manera consistente en diferentes entornos.
Además, la aplicación puede ser desplegada en Kubernetes para escalar en un clúster y manejar múltiples instancias de manera eficiente.
Impacto y beneficios.
El impacto de este proyecto es significativo en áreas donde se requiere la identificación rápida de personas. Algunos beneficios:
- Seguridad: Puede ser utilizado en sistemas de vigilancia para identificar personas en tiempo real.
- Control de acceso: Se puede aplicar en sistemas de control de acceso, donde solo las personas autorizadas pueden ingresar.
- Escalabilidad: Gracias al uso de Docker y Kubernetes, la aplicación puede escalarse para ser utilizada en múltiples ubicaciones con alta eficiencia.
Desafíos y limitaciones.
- Calidad de las imágenes: Si las imágenes son de baja resolución o tienen poca iluminación, el modelo puede tener dificultades para detectar y reconocer los rostros. Incluso realizando un preprocesado de las imágenes he tenido problemas.
- Precisión: Aunque en mi caso, con solo 4 fotografías, el modelo ha sido preciso, la precisión puede disminuir en entornos reales.
- Coste computacional: He tenido problemas de rendimiento especialmente en lo referente a la detección, pese a utilizar un ordenador con altas capacidades de procesado y una buena tarjeta gráfica. Incluso con videos de baja resolución.
Futuras mejoras en próximos pasos.
- Mejorar la precisión: Incluir más datos para mejorar la precisión del modelo y reducir los falsos positivos y negativos.
- Optimización de rendimiento: Implementar técnicas de optimización para mejorar la velocidad del procesamiento de imágenes en tiempo real.
- Ampliar el uso de la IA: Incluir análisis más avanzados como la detección de emociones o seguimiento de rostros.
- Mejorar la seguridad de los datos: Implementar mejores prácticas para la encriptación de las codificaciones faciales y mejorar la gestión de la privacidad.
- Desplegar en entornos en la nube: Integrar el despliegue con plataformas de la nube como AWS, Google Cloud o Azure para un mejor rendimiento y escalabilidad.
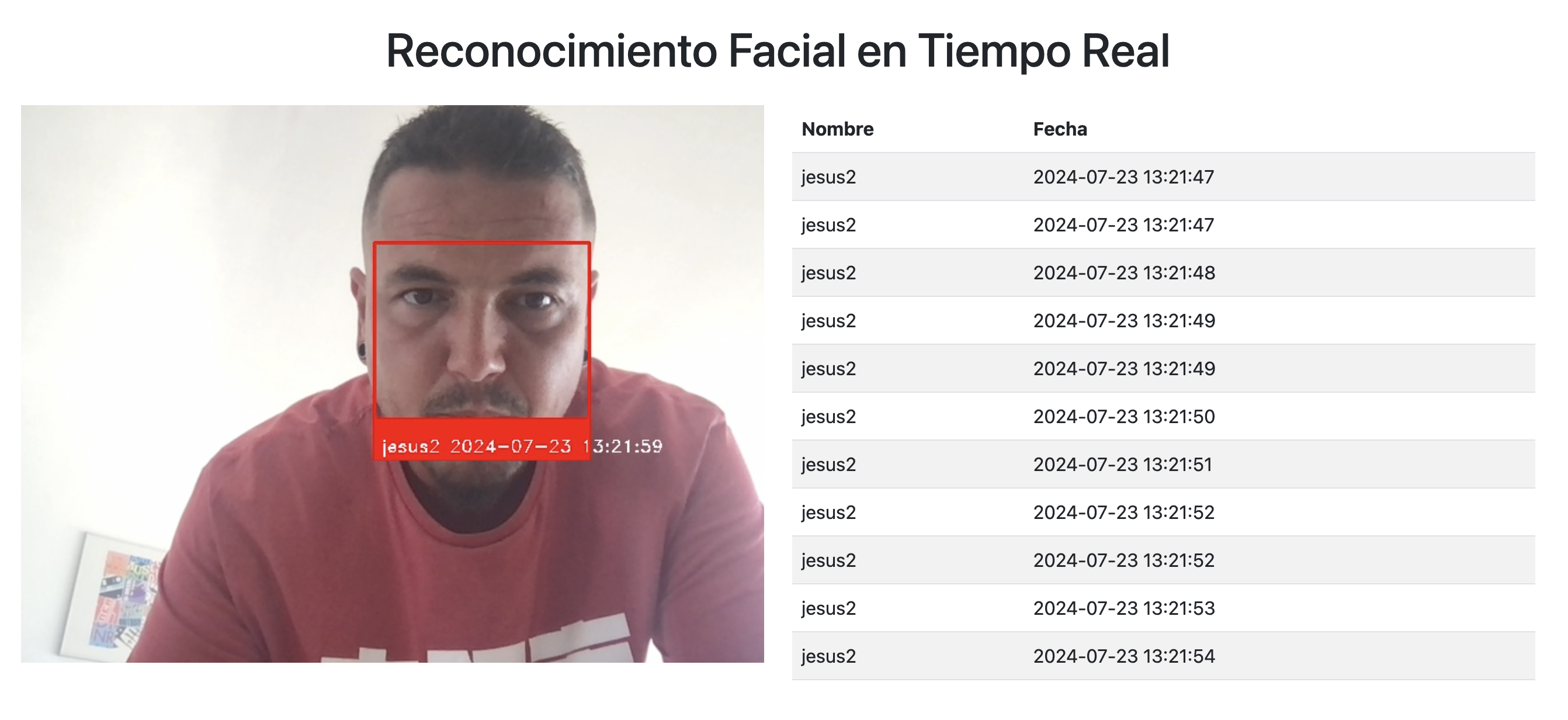
Muestra del interfaz en funcionamiento
Documento Google Sheets
Enlace al documento de Google Sheets: (https://docs.google.com/spreadsheets/d/1hh5TTBP-mkEjpn4RhzDrvrUvHvLNrtUXIvIQxjpIKAU/edit?usp=sharing)
Referencias
- Repositorio del proyecto en GitHub, con instrucciones para el desarrollo y despliegue de la aplicación: (https://github.com/jhmarina/app-reconocimiento-facial)
- Artículos en este blog detallando el proceso de desarrollo:
Conclusión
A lo largo del curso, nos hemos centrado en la creación de modelos y la implementación de diversas técnicas de IA. Sin embargo, en este proyecto específico, no fue necesario construir un modelo desde cero, ya que utilicé un modelo preentrenado de reconocimiento facial. Aunque el modelo estaba listo para su uso, el desarrollo del proyecto me permitió aplicar conceptos clave aprendidos durante el curso, especialmente en cuanto al preprocesamiento de datos, en concreto en el preprocesamiento de las imágenes.
Mi objetivo era combinar la teoría aprendida en el curso con mi experiencia en desarrollo de productos, enfocándome en la creación de una solución funcional que no solo tuviera una base de IA, sino que también pudiera ser desplegada y gestionada eficientemente en un entorno de producción.
En resumen, aunque no implementé técnicas avanzadas de modelado en este proyecto, sí utilicé muchos de los conceptos aprendidos durante el curso para enfrentar los desafíos técnicos y lograr mi objetivo de crear una aplicación completa y práctica dentro del ámbito de desarrollo web y despliegue en Kubernetes.